author:nforcex
J2EE(JAVA语言)特点:
口号:“只写一次,随处运行。”因为JVM的缘故,使之具有跨平台的兼容性-JVM是java源程序的编译运行跟硬件无关。正是因为它的这一特性,使它在大量使用UNIX、Linux的大型企业级应用领域大放异彩(这一领域正对应SUN公司的J2EE);而对于平台多样化的PDA、Smart Phone以及Smart Watch也是不断地攻城拔寨,占有了大量的市场份额。而桌面市场和中小型企业应用在很大程度上都是Win32/64平台的天下,所以它的这一特性在这一领域并不灵,.NET和J2EE的中小企业应用在这里进行着难解难分平分秋色的较量。
因为它的各项完全的面向对象语言特性,以及高安全性的特性,使之为世人称颂,甚至连微软总裁比尔▪盖茨对之都赞誉有加。
值得称谓的是JAVA的发明主体SUN公司在经过一段时间的摸索之后,确定了JAVA语言的重点发展方向:企业级应用和嵌入式设备领域,它们分别对应于 SUN公司发布的J2EE架构和J2ME架构。而.NET架构却被微软不断地吹嘘成各种各样的口号,诸如“革命性的新平台、构建于开放的Internet 协议和标准之上,并提供了工具和服务、以新的方式融合计算和通讯”、“让每台电脑都运行图形界面”、“让每台桌子都有上电脑,让每台电脑里都跑微软的软件”说了许许多多抽象的概念(与其说是概念不如说是废话),它让我们越看.NET越不知道它到底是干什么的,原因很简单,它定位模糊,哪个领域都想沾,从而没有针对性没有一个明显的范畴。所以说,.NET缺乏明确的战略。不过.NET仍算是代表最高技术的超级软件平台。
也许曾经EJB是J2EE的全部核心内容所在,但是现在它却逐步被一些轻量级架构取代(这一现象会在EJB3.0发布以后改观)。
.NET(C++,C#,VB,VJ++语言)特点:
它有许许多多令人称道的特性:
1。譬如高安全性(.NET架构在受管的运行时环境、对数组作运行时越界检查、防止缓冲区溢出、组织特洛伊木马方面颇有建树)
2。CLR(Common Language Runtime 通用语言运行时,CLR是一套标准资源,理论上可以被任何.NET程序所利用,而不管使用哪种编程语言。)
CLR资源:
面向对象的编程模型(继承、多态、异常处理和垃圾收集等)
●安全模式
●类型系统
●所有.NET基类
●许多.NET framework类
●开发、调试和评测(profiling)工具
●执行和代码管理
●1L到本地代码(1L-to-native)转换器和优化器
3。 CLS(Common Language Specification 通用语言规范)所有的.NET语言都支持它。它的设计出发点在于:任何使用CLS兼容的类型的程序,都可以和以任何语言编写的.NET程序进行互操作。理论上,这允许在不同的.NET语言之间,进行非常紧密的互操作,比方说,允许一个C#类从一个VB类继承下来。
.NET提供的平台也不仅仅是 Windows平台了,除了微软的Win32/64平台之外,还有Novell Mono、DotGNU Portable.NET。装置也有所增加:Server、PC、PDA、Smart Phone、Smart Watch。开发工具和语言也有所增加:Visual Studio系列语言、Dephi、Eiffel。由此可见,微软的影响力是巨大的,JAVA花了近十年才办到的事情,.NET只花了三年,这样的爆发力确实惊人
4。.NET平台拥有着极为强大和易用的IDE:Visual Studio 2005。这是JAVA各个框架、架构所缺乏的。注:JBiuder的易用性还是和VS 2005有很大差距。
ps:在今年Jolt 2006大奖的ENTERPRISE PROJECT MANAGEMENT项目,Visual Studio Team System 2005 (Microsoft) 荣获了Productivity Winners。
C++/CLI的特点:
近些年来C++在GP(范型程序设计)方面大放异彩,而2005年微软新推出的C++/CLI着实翻起了一些波澜。C++/CLI像是一座桥梁,将原本属于静态世界的C++与动态的CLI联系起来。但是C++/CLI的复杂性与过去的C++相比有增无减,并且C++代码也变得面目全非。
2007年5月30日星期三
2007年5月29日星期二
国民素质确实低下,亦缺乏内心自省
author:nforcex
看到韩寒的博文《传统美德》,文章说中国国民素质低下,然后引来一大群低素质的网友进行谩骂。如果他们对韩寒的大胆"性"言论于未成年人的不利影响表示异议或愤慨我还尚表示赞同,但相当多的人所持观点无非是不承认中华民族国民素质的低下。想必能够独立思考的人对于中国人是否素质低下早已了然于心,但是鉴于国民善用思维的“模糊论”,我们不得不讨论下中国人的劣根性与国民素质。
中国人缺乏内心自省,同时也缺乏实证主义。这两大特性就像一对孪生兄弟一样相互缠绕,腐朽而不可救药。中国人一套为人处世的思维方式被自己骄傲地称作模糊思维、系统论。令人感到可笑与幼稚。
由此[ps1]可以看出,了解中华文化特性的钥匙就是:面子。中国人为了保全面子不惜扭曲事实,一旦丢掉面子就会撕破脸皮进行无耻谩骂、甚至恶毒陷害,等等...
自己判断自己未免主观,我们来听听别人是怎么说的。我记得看过一位在中国生活过的美国传教士亚瑟·亨·史密斯的著作--《中国人的性格》。该书的内容1890年曾在上海的英文版报纸《华北每日新闻》发表,轰动一时。这位人品尚可的传教士在中国生活了22年,鲁迅先生对他也尊敬有加。他在该书中尽量客观公正地评价中国人,对中国人的特征有褒有贬,今天我们就事论事,仅谈到了涉及中国人劣根性的一些特性。鲁迅先生一直希望有人翻译这本书,在他逝世前14天发表的《“立此存照”(三)》中,先生还提到:“我至今还在希望有人翻译出斯密斯的《支那人气质》来。看了这些,而自省,分析,明白哪几点说的对,变革,挣扎,自做工夫,却不求别人的原谅和称赞,来证明究竟怎样的是中国人。” 时过境迁,已经是130多年后的2007年了,中国人的缺点竟然“完美”地完整保存下来。作为读者,我唏嘘不已。作为一个有良知的中国人,我感到悲哀。
大的方面我们不说,暂且不谈什么民族的劣根性。就单从小的方面--国民素质,很多中国人死不承认中国的国民素质相当低下。
那么请看到我这篇文章的读者实事求是地进行一下自我判断:
1.该排队的时候你插队了吗?规定一米线的地方你做到了吗? 积极的答案:否
2.你会不会经常性的随地扔纸和吐痰? 积极的答案:否
3.你如果是商人是否会公买公卖,而不去欺诈顾客,甚至有假冒伪劣产品? 积极的答案:否
4. 在公交车上面坐着的时候,看到有老人或孕妇上车,你有让座吗? 积极的答案:是
5.如果你看到某人掉了几百元钱,你会不会追上去将拾起来的钱给他? 积极的答案:是
6.如果有商场在下雨的时候派发雨伞,并说明改日请送还,你会不会再将雨伞送回去? 积极的答案:是
7.如果你所在的小区宽带容量有限,如果你的bt下载不限制连接数量就会导致本楼其他人连打开网页都极度缓慢,你会不会自觉限制bt连接数量? 积极的答案:是
8.上公共厕所你是否不仅不充水甚至会将排泄物拉/撒到池子的外面? 积极的答案:否
9.随地大小便了吗?即便是你家的小孩? 积极的答案:否
10.公共场所你大声喧哗了吗?意识得到什么是大声喧哗吗? 积极的答案:不可以大声喧哗
11.你懂什么是在保证自己最起码生存权、自尊权前提下我们人有义务维护社会秩序吗? 你有身体力行吗? 积极的答案:是
如果上述回答有至少1/3都是消极的答案,很遗憾的告诉你,你属于素质低下的国民。
ps1:不情愿内心自省和不愿意实事求是就是因为死要面子活受罪,它们之间不存在必然的因果关系,但是存在可能的正反关系。如果你具有丰富的社会经验,你就会自己分析出这两大“特性”和“要面子”存在着必然的正反关系。
看到韩寒的博文《传统美德》,文章说中国国民素质低下,然后引来一大群低素质的网友进行谩骂。如果他们对韩寒的大胆"性"言论于未成年人的不利影响表示异议或愤慨我还尚表示赞同,但相当多的人所持观点无非是不承认中华民族国民素质的低下。想必能够独立思考的人对于中国人是否素质低下早已了然于心,但是鉴于国民善用思维的“模糊论”,我们不得不讨论下中国人的劣根性与国民素质。
中国人缺乏内心自省,同时也缺乏实证主义。这两大特性就像一对孪生兄弟一样相互缠绕,腐朽而不可救药。中国人一套为人处世的思维方式被自己骄傲地称作模糊思维、系统论。令人感到可笑与幼稚。
由此[ps1]可以看出,了解中华文化特性的钥匙就是:面子。中国人为了保全面子不惜扭曲事实,一旦丢掉面子就会撕破脸皮进行无耻谩骂、甚至恶毒陷害,等等...
自己判断自己未免主观,我们来听听别人是怎么说的。我记得看过一位在中国生活过的美国传教士亚瑟·亨·史密斯的著作--《中国人的性格》。该书的内容1890年曾在上海的英文版报纸《华北每日新闻》发表,轰动一时。这位人品尚可的传教士在中国生活了22年,鲁迅先生对他也尊敬有加。他在该书中尽量客观公正地评价中国人,对中国人的特征有褒有贬,今天我们就事论事,仅谈到了涉及中国人劣根性的一些特性。鲁迅先生一直希望有人翻译这本书,在他逝世前14天发表的《“立此存照”(三)》中,先生还提到:“我至今还在希望有人翻译出斯密斯的《支那人气质》来。看了这些,而自省,分析,明白哪几点说的对,变革,挣扎,自做工夫,却不求别人的原谅和称赞,来证明究竟怎样的是中国人。” 时过境迁,已经是130多年后的2007年了,中国人的缺点竟然“完美”地完整保存下来。作为读者,我唏嘘不已。作为一个有良知的中国人,我感到悲哀。
大的方面我们不说,暂且不谈什么民族的劣根性。就单从小的方面--国民素质,很多中国人死不承认中国的国民素质相当低下。
那么请看到我这篇文章的读者实事求是地进行一下自我判断:
1.该排队的时候你插队了吗?规定一米线的地方你做到了吗? 积极的答案:否
2.你会不会经常性的随地扔纸和吐痰? 积极的答案:否
3.你如果是商人是否会公买公卖,而不去欺诈顾客,甚至有假冒伪劣产品? 积极的答案:否
4. 在公交车上面坐着的时候,看到有老人或孕妇上车,你有让座吗? 积极的答案:是
5.如果你看到某人掉了几百元钱,你会不会追上去将拾起来的钱给他? 积极的答案:是
6.如果有商场在下雨的时候派发雨伞,并说明改日请送还,你会不会再将雨伞送回去? 积极的答案:是
7.如果你所在的小区宽带容量有限,如果你的bt下载不限制连接数量就会导致本楼其他人连打开网页都极度缓慢,你会不会自觉限制bt连接数量? 积极的答案:是
8.上公共厕所你是否不仅不充水甚至会将排泄物拉/撒到池子的外面? 积极的答案:否
9.随地大小便了吗?即便是你家的小孩? 积极的答案:否
10.公共场所你大声喧哗了吗?意识得到什么是大声喧哗吗? 积极的答案:不可以大声喧哗
11.你懂什么是在保证自己最起码生存权、自尊权前提下我们人有义务维护社会秩序吗? 你有身体力行吗? 积极的答案:是
如果上述回答有至少1/3都是消极的答案,很遗憾的告诉你,你属于素质低下的国民。
ps1:不情愿内心自省和不愿意实事求是就是因为死要面子活受罪,它们之间不存在必然的因果关系,但是存在可能的正反关系。如果你具有丰富的社会经验,你就会自己分析出这两大“特性”和“要面子”存在着必然的正反关系。
2007年5月25日星期五
SOA示意图_摘自Wikipedia
SOA definitions
SOA is a design for linking business and computational resources (principally organizations, applications and data) on demand to achieve the desired results for service consumers (which can be end users or other services). OASIS (the Organization for the Advancement of Structured Information Standards) defines SOA as the following:
A paradigm for organizing and utilizing distributed capabilities that may be under the control of different ownership domains. It provides a uniform means to offer, discover, interact with and use capabilities to produce desired effects consistent with measurable preconditions and expectations.
There are multiple definitions of SOA, the OASIS group and the Open Group have created formal definition with depth which can be applied to both the technology and business domains.
Open Group SOA Definition (SOA-Definition)[3]
OASIS SOA Reference Model (SOA-RM)[4]
What Is Service-Oriented Architecture? (XML.com)
What is Service-Oriented Architecture? (Javaworld.com)
Webopedia definition
TechEncyclopedia definition
Object Management Group (OMG ) SOA Special Interest Group definition
WhatIs.com definition
SearchWebServices.com Numerous SOA definitions by industry experts
Though many definitions of SOA limit themselves to technology or just web services, this is predominantly pushed by technology vendors; in 2003 they talked just of web services, while in 2006 the talk is of events and process engines.
Why SOA?
The main drivers for SOA adoption are that it links computational resources and promotes their reuse. Enterprise architects believe that SOA can help businesses respond more quickly and cost-effectively to changing market conditions[5] . This style of architecture promotes reuse at the macro (service) level rather than micro level (objects). It can also simplify interconnection to - and usage of - existing IT (legacy) assets.
SOA Practitioners Guide: Why Services-Oriented Architecture? provides a high-level summary on SOA.
In some respects, SOA can be considered an architectural evolution rather than a revolution and captures many of the best practices of previous software architectures. In communications systems, for example, there has been little development of solutions that use truly static bindings to talk to other equipment in the network. By formally embracing a SOA approach, such systems are better positioned to stress the importance of well-defined, highly inter-operable interfaces.[citation needed]
Some have questioned whether SOA is just a revival of modular programming (1970s), event-oriented design (1980s) or interface/component-based design (1990s)[citation needed]. SOA promotes the goal of separating users (consumers) from the service implementations. Services can therefore be run on various distributed platforms and be accessed across networks. This can also maximise reuse of services[citation needed].
SOA principles
The following guiding principles define the ground rules for development, maintenance, and usage of the SOA[6]
Reuse, granularity, modularity, composability, componentization, and interoperability
Compliance to standards (both common and industry-specific)
Services identification and categorization, provisioning and delivery, and monitoring and tracking
The following specific architectural principles for design and service definition focus on specific themes that influence the intrinsic behaviour of a system and the style of its design:
Service Encapsulation
Service Loose coupling - Services maintain a relationship that minimizes dependencies and only requires that they maintain an awareness of each other
Service contract - Services adhere to a communications agreement, as defined collectively by one or more service description documents
Service abstraction - Beyond what is described in the service contract, services hide logic from the outside world
Service reusability - Logic is divided into services with the intention of promoting reuse
Service composability - Collections of services can be coordinated and assembled to form composite services
Service autonomy – Services have control over the logic they encapsulate
Service optimization – All else equal, high-quality services are generally considered preferable to low-quality ones
Service discoverability – Services are designed to be outwardly descriptive so that they can be found and assessed via available discovery mechanisms[7]
In addition, the following factors should also be taken into account when defining a SOA implementation:
SOA Reference Architecture SOA Practitioners Guide Part 2: SOA Reference Architecture covers the SOA Reference Architecture, which provides a worked design of an enterprise-wide SOA implementation with detailed architecture diagrams, component descriptions, detailed requirements, design patterns, opinions about standards, patterns on regulation compliance, standards templates etc.
Life cycle management SOA Practitioners Guide Part 3: Introduction to Services Lifecycle introduces the Services Lifecycle and provides a detailed process for services management though the service lifecycle, from inception through to retirement or repurposing of the services. It also contains an appendix that includes organization and governance best practices, templates, comments on key SOA standards, and recommended links for more information.
Efficient use of system resources
Service maturity and performance
EAI Enterprise Application Integration
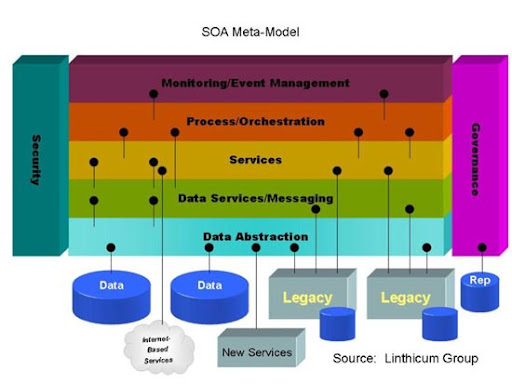
SOA Elements
SOA is a design for linking business and computational resources (principally organizations, applications and data) on demand to achieve the desired results for service consumers (which can be end users or other services). OASIS (the Organization for the Advancement of Structured Information Standards) defines SOA as the following:
A paradigm for organizing and utilizing distributed capabilities that may be under the control of different ownership domains. It provides a uniform means to offer, discover, interact with and use capabilities to produce desired effects consistent with measurable preconditions and expectations.
There are multiple definitions of SOA, the OASIS group and the Open Group have created formal definition with depth which can be applied to both the technology and business domains.
Open Group SOA Definition (SOA-Definition)[3]
OASIS SOA Reference Model (SOA-RM)[4]
What Is Service-Oriented Architecture? (XML.com)
What is Service-Oriented Architecture? (Javaworld.com)
Webopedia definition
TechEncyclopedia definition
Object Management Group (OMG ) SOA Special Interest Group definition
WhatIs.com definition
SearchWebServices.com Numerous SOA definitions by industry experts
Though many definitions of SOA limit themselves to technology or just web services, this is predominantly pushed by technology vendors; in 2003 they talked just of web services, while in 2006 the talk is of events and process engines.
Why SOA?
The main drivers for SOA adoption are that it links computational resources and promotes their reuse. Enterprise architects believe that SOA can help businesses respond more quickly and cost-effectively to changing market conditions[5] . This style of architecture promotes reuse at the macro (service) level rather than micro level (objects). It can also simplify interconnection to - and usage of - existing IT (legacy) assets.
SOA Practitioners Guide: Why Services-Oriented Architecture? provides a high-level summary on SOA.
In some respects, SOA can be considered an architectural evolution rather than a revolution and captures many of the best practices of previous software architectures. In communications systems, for example, there has been little development of solutions that use truly static bindings to talk to other equipment in the network. By formally embracing a SOA approach, such systems are better positioned to stress the importance of well-defined, highly inter-operable interfaces.[citation needed]
Some have questioned whether SOA is just a revival of modular programming (1970s), event-oriented design (1980s) or interface/component-based design (1990s)[citation needed]. SOA promotes the goal of separating users (consumers) from the service implementations. Services can therefore be run on various distributed platforms and be accessed across networks. This can also maximise reuse of services[citation needed].
SOA principles
The following guiding principles define the ground rules for development, maintenance, and usage of the SOA[6]
Reuse, granularity, modularity, composability, componentization, and interoperability
Compliance to standards (both common and industry-specific)
Services identification and categorization, provisioning and delivery, and monitoring and tracking
The following specific architectural principles for design and service definition focus on specific themes that influence the intrinsic behaviour of a system and the style of its design:
Service Encapsulation
Service Loose coupling - Services maintain a relationship that minimizes dependencies and only requires that they maintain an awareness of each other
Service contract - Services adhere to a communications agreement, as defined collectively by one or more service description documents
Service abstraction - Beyond what is described in the service contract, services hide logic from the outside world
Service reusability - Logic is divided into services with the intention of promoting reuse
Service composability - Collections of services can be coordinated and assembled to form composite services
Service autonomy – Services have control over the logic they encapsulate
Service optimization – All else equal, high-quality services are generally considered preferable to low-quality ones
Service discoverability – Services are designed to be outwardly descriptive so that they can be found and assessed via available discovery mechanisms[7]
In addition, the following factors should also be taken into account when defining a SOA implementation:
SOA Reference Architecture SOA Practitioners Guide Part 2: SOA Reference Architecture covers the SOA Reference Architecture, which provides a worked design of an enterprise-wide SOA implementation with detailed architecture diagrams, component descriptions, detailed requirements, design patterns, opinions about standards, patterns on regulation compliance, standards templates etc.
Life cycle management SOA Practitioners Guide Part 3: Introduction to Services Lifecycle introduces the Services Lifecycle and provides a detailed process for services management though the service lifecycle, from inception through to retirement or repurposing of the services. It also contains an appendix that includes organization and governance best practices, templates, comments on key SOA standards, and recommended links for more information.
Efficient use of system resources
Service maturity and performance
EAI Enterprise Application Integration
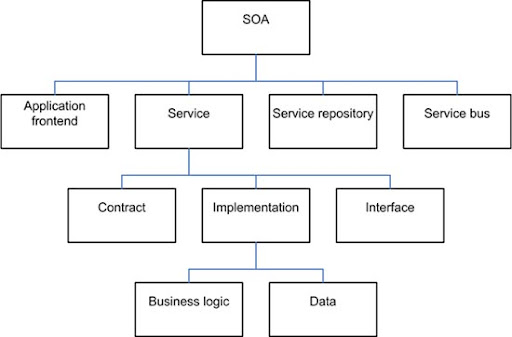
SOA Elements
网络OSI模型的经典比喻_摘自wikipedia
OSI模型,即开放式通信系统互联参考模型(Open System Interconnection),是国际标准化组织(ISO)提出的一个试图使各种计算机在世界范围内互连为网络的标准框架,简称OSI。
层次划分
OSI将计算机网络体系结构(architecture)划分为以下七层:
7 应用层:Application Layer
6 展现层:Presentation Layer (中国大陆:表示层)
5 会谈层:Session Layer (中国大陆:会话层)
4 传输层:Transport Layer
3 网络层:Network Layer (中国大陆:网络层)
2 资料链结层:Data Link Layer (中国大陆:数据链路层)
1 实体层:Physical Layer (中国大陆:物理层)
“OSI/RM”是英文“Open Systems Interconnection Reference Model”的缩写。
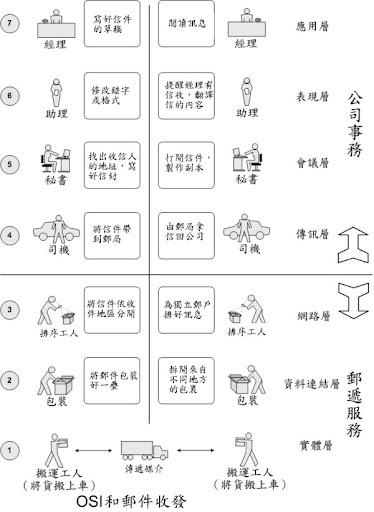
7 应用层:老板
6 展现层:相当于公司中简报老板、替老板写信的助理
5 会谈层:相当于公司中收寄信、写信封与拆信封的秘书
4 传输层:相当于公司中跑邮局的送信职员
3 网络层:相当于邮局中的排序工人
2 资料链结层:相当于邮局中的装拆箱工人
1 实体层:相当于邮局中的搬运工人
历史
在制定计算机网络标准方面,起着重大作用的两大国际组织是:国际电报与电话咨询委员会(CCITT),与国际标准化组织(ISO),虽然它们工作领域不同,但随着科学技术的发展,通信与信息处理之间的界限开始变得比较模糊,这也成了CCITT和ISO共同关心的领域。1974年,ISO发布了著名的ISO/IEC 7498标准,它定义了网络互联的7层框架,也就是开放式系统互连参考模型。
影响
OSI是一个定义良好的协议规范集,并有许多可选部分完成类似的任务。它定义了开放系统的层次结构、层次之间的相互关系以及各层所包括的可能的任务。是作为一个框架来协调和组织各层所提供的服务。OSI参考模型并没有提供一个可以实现的方法,而是描述了一些概念,用来协调进程间通信标准的制定。即OSI参考模型并不是一个标准,而是一个在制定标准时所使用的概念性框架。
层次划分
OSI将计算机网络体系结构(architecture)划分为以下七层:
7 应用层:Application Layer
6 展现层:Presentation Layer (中国大陆:表示层)
5 会谈层:Session Layer (中国大陆:会话层)
4 传输层:Transport Layer
3 网络层:Network Layer (中国大陆:网络层)
2 资料链结层:Data Link Layer (中国大陆:数据链路层)
1 实体层:Physical Layer (中国大陆:物理层)
“OSI/RM”是英文“Open Systems Interconnection Reference Model”的缩写。
7 应用层:老板
6 展现层:相当于公司中简报老板、替老板写信的助理
5 会谈层:相当于公司中收寄信、写信封与拆信封的秘书
4 传输层:相当于公司中跑邮局的送信职员
3 网络层:相当于邮局中的排序工人
2 资料链结层:相当于邮局中的装拆箱工人
1 实体层:相当于邮局中的搬运工人
历史
在制定计算机网络标准方面,起着重大作用的两大国际组织是:国际电报与电话咨询委员会(CCITT),与国际标准化组织(ISO),虽然它们工作领域不同,但随着科学技术的发展,通信与信息处理之间的界限开始变得比较模糊,这也成了CCITT和ISO共同关心的领域。1974年,ISO发布了著名的ISO/IEC 7498标准,它定义了网络互联的7层框架,也就是开放式系统互连参考模型。
影响
OSI是一个定义良好的协议规范集,并有许多可选部分完成类似的任务。它定义了开放系统的层次结构、层次之间的相互关系以及各层所包括的可能的任务。是作为一个框架来协调和组织各层所提供的服务。OSI参考模型并没有提供一个可以实现的方法,而是描述了一些概念,用来协调进程间通信标准的制定。即OSI参考模型并不是一个标准,而是一个在制定标准时所使用的概念性框架。
2007年5月24日星期四
2007年5月22日星期二
中国会有这样的婚恋搭配么?
author:nforcex
中国会有这样的婚恋搭配么?似乎不可能,即使少而又少地有也往往有着特殊的企图。
《越狱》中扮演L.J的演员和他老婆

凭借《绝望的主妇》一炮而红的伊娃·朗戈里亚将于2007年6月7日和比自己小7岁的男友NBA球星帕克举行婚礼。
身高上男低女高,年龄上男小女大,甚至经济上女的更加富有,这种现象在西方并不奇怪,只要他们之间的差距不是太极端。
或许有人会说那是特例,但是台湾和欧美的综艺节目抑或是名人不止一次地提到过:在发展中国家,人们往往由于连温饱问题都不能很好解决,在婚姻问题上也就将追求真爱让位于追求物质。
中国会有这样的婚恋搭配么?似乎不可能,即使少而又少地有也往往有着特殊的企图。
《越狱》中扮演L.J的演员和他老婆
凭借《绝望的主妇》一炮而红的伊娃·朗戈里亚将于2007年6月7日和比自己小7岁的男友NBA球星帕克举行婚礼。
身高上男低女高,年龄上男小女大,甚至经济上女的更加富有,这种现象在西方并不奇怪,只要他们之间的差距不是太极端。
或许有人会说那是特例,但是台湾和欧美的综艺节目抑或是名人不止一次地提到过:在发展中国家,人们往往由于连温饱问题都不能很好解决,在婚姻问题上也就将追求真爱让位于追求物质。
2007年5月21日星期一
Unbuntu试用感受
昨晚安装了Linux系列中的Unbuntu 7.0.4,果然像Unbuntu社区宣称的那样,易用性非比寻常。我的电脑是Athlon64 X2 4800+ & AMD 690G芯片组 & Realtek8111 {10/100/1000 Mbps PCI Express x1 Gigabit Ethernet} & WD3200KS 的配置,安装Unbuntu 7.0.4竟然不需要通过重新编译内核的方式来配置驱动程序-----对了,可以直接认出所有硬件。So good,甚至比Windows 2000 Professional还要强。
记得曾经看过国内某计算机杂志引述国外专家的预测,“Linux的易用性在2007年达到Windows 2000 Professional的水平”。现在回过头来看这则预言,真是佩服得五体投地。
记得曾经看过国内某计算机杂志引述国外专家的预测,“Linux的易用性在2007年达到Windows 2000 Professional的水平”。现在回过头来看这则预言,真是佩服得五体投地。
2007年5月14日星期一
哪些CPU支持AMD-V(Pacifica)或者Intel VT~~~~X86 virtualization
author:nforcex
AMD(TM)HVM should work with all CPU's in the AMD-V (SVM) series. The desktop processors must be for the "socket AM2" with DDR2 and F2 stepping that are not Sempron brand.
看这则英文资料,所有AM2接口的采用F2步进同时不是闪龙的CPU全部支持代号为Pacifica的AMD-V硬件虚拟化功能。
The list:
* Athlon™ 64 3800+
* Athlon™ 64 3500+
* Athlon™ 64 3200+
* Athlon™ 64 3000+
* Athlon™ 64 FX-62
* Athlon™ 64 FX-70(Quad FX Platform)
* Athlon™ 64 FX-72(Quad FX Platform)
* Athlon™ 64 FX-74(Quad FX Platform)
* Athlon™ 64 X2 Dual-Core 5000+
* Athlon™ 64 X2 Dual-Core 4800+
* Athlon™ 64 X2 Dual-Core 4600+
* Athlon™ 64 X2 Dual-Core 4400+
* Athlon™ 64 X2 Dual-Core 4200+
* Athlon™ 64 X2 Dual-Core 4000+
* Athlon™ 64 X2 Dual-Core 3800+
* Turion(TM) 64 X2 TL-60
* Turion(TM) 64 X2 TL-56
* Turion(TM) 64 X2 TL-52
* Turion(TM) 64 X2 TL-50
the Opteron which is:
* 1000 Series
* 2000 Series
* 8000 Series
而支持VT也就是Intel相应硬件虚拟机功能的CPU列表如下:
* Intel® 2 Core(TM) Duo Extreme processor X6800
* Intel® 2 Core(TM) Duo processor E6700
* Intel® 2 Core(TM) Duo processor E6600
* Intel® 2 Core(TM) Duo processor E6400
* Intel® 2 Core(TM) Duo processor E6300
* Intel® Core(TM) Duo processor T2600
* Intel® Core(TM) Duo processor T2500
* Intel® Core(TM) Duo processor T2400
* Intel® Core(TM) Duo processor L2300
* Intel® Pentium® processor Extreme Edition 965
* Intel® Pentium® processor Extreme Edition 955
* Intel® Pentium® D processor 960
* Intel® Pentium® D processor 950
* Intel® Pentium® D processor 940
* Intel® Pentium® D processor 930
* Intel® Pentium® D processor 920
* Intel® Pentium® 4 processor 672
* Intel® Pentium® 4 processor 662
* Intel® Xeon® processor 7041
* Intel® Xeon® processor 7040
* Intel® Xeon® processor 7030
* Intel® Xeon® processor 7020
* Intel® Xeon® processor 5080
* Intel® Xeon® processor 5063
* Intel® Xeon® processor 5060
* Intel® Xeon® processor 5050
* Intel® Xeon® processor 5030
Intel® Virtualization Technology requires a computer system with an enabled Intel® processor, BIOS, virtual machine monitor (VMM) and for some uses, certain platform software enabled for it. Functionality,performance or other benefits will vary depending on hardware andsoftware configurations. Intel Virtualization Technology-enabled BIOS and VMM applications are currently in development.
看上文,Intel公司资料里说的是些废话,就是说该技术的运作需要相应CPU、BIOS、和虚拟机软件来支持。
AMD(TM)HVM should work with all CPU's in the AMD-V (SVM) series. The desktop processors must be for the "socket AM2" with DDR2 and F2 stepping that are not Sempron brand.
看这则英文资料,所有AM2接口的采用F2步进同时不是闪龙的CPU全部支持代号为Pacifica的AMD-V硬件虚拟化功能。
The list:
* Athlon™ 64 3800+
* Athlon™ 64 3500+
* Athlon™ 64 3200+
* Athlon™ 64 3000+
* Athlon™ 64 FX-62
* Athlon™ 64 FX-70(Quad FX Platform)
* Athlon™ 64 FX-72(Quad FX Platform)
* Athlon™ 64 FX-74(Quad FX Platform)
* Athlon™ 64 X2 Dual-Core 5000+
* Athlon™ 64 X2 Dual-Core 4800+
* Athlon™ 64 X2 Dual-Core 4600+
* Athlon™ 64 X2 Dual-Core 4400+
* Athlon™ 64 X2 Dual-Core 4200+
* Athlon™ 64 X2 Dual-Core 4000+
* Athlon™ 64 X2 Dual-Core 3800+
* Turion(TM) 64 X2 TL-60
* Turion(TM) 64 X2 TL-56
* Turion(TM) 64 X2 TL-52
* Turion(TM) 64 X2 TL-50
the Opteron which is:
* 1000 Series
* 2000 Series
* 8000 Series
而支持VT也就是Intel相应硬件虚拟机功能的CPU列表如下:
* Intel® 2 Core(TM) Duo Extreme processor X6800
* Intel® 2 Core(TM) Duo processor E6700
* Intel® 2 Core(TM) Duo processor E6600
* Intel® 2 Core(TM) Duo processor E6400
* Intel® 2 Core(TM) Duo processor E6300
* Intel® Core(TM) Duo processor T2600
* Intel® Core(TM) Duo processor T2500
* Intel® Core(TM) Duo processor T2400
* Intel® Core(TM) Duo processor L2300
* Intel® Pentium® processor Extreme Edition 965
* Intel® Pentium® processor Extreme Edition 955
* Intel® Pentium® D processor 960
* Intel® Pentium® D processor 950
* Intel® Pentium® D processor 940
* Intel® Pentium® D processor 930
* Intel® Pentium® D processor 920
* Intel® Pentium® 4 processor 672
* Intel® Pentium® 4 processor 662
* Intel® Xeon® processor 7041
* Intel® Xeon® processor 7040
* Intel® Xeon® processor 7030
* Intel® Xeon® processor 7020
* Intel® Xeon® processor 5080
* Intel® Xeon® processor 5063
* Intel® Xeon® processor 5060
* Intel® Xeon® processor 5050
* Intel® Xeon® processor 5030
Intel® Virtualization Technology requires a computer system with an enabled Intel® processor, BIOS, virtual machine monitor (VMM) and for some uses, certain platform software enabled for it. Functionality,performance or other benefits will vary depending on hardware andsoftware configurations. Intel Virtualization Technology-enabled BIOS and VMM applications are currently in development.
看上文,Intel公司资料里说的是些废话,就是说该技术的运作需要相应CPU、BIOS、和虚拟机软件来支持。
有这样的同学,幸甚、幸甚
author:nforcex
昨天某同学到我家一起做游戏设计。做完聊天,彼此天南地北的胡侃,知道了很多有趣和生动的事情。她是一名大学辅导员,在处理班务的时候,她总是站在真正是非曲直的角度,站在学生的角度。看起来很像《极道鲜师Ⅱ》上的 山口久美子,并且一样是年轻的女老师[跟学生几乎一样大],同时也是 a bit beautiful。
领导向她施压要她评优评奖学金照顾走关系的人,她置之不理;学生只要不是真的人品不好或做错了什么可以跟她开玩笑,还能跟着她蹭饭;偶然自己的手机打错电话对方知道她是女的疯狂骚扰,她找一帮学生反过来恶搞那个男的,还骗他到世纪欢乐园放了一下午鸽子;同事生病了会跑去照顾;最看不起那些不靠自己本事只会混关系耍深沉打酒令的人~~~~~~~
也许在中国,这个人脉关系当道的社会,作为成人不得不妥协。但是我仍然敬仰敬佩我的这位真性情的同学。
有这样的同学,并且可以做朋友,真是幸甚、幸甚。
昨天某同学到我家一起做游戏设计。做完聊天,彼此天南地北的胡侃,知道了很多有趣和生动的事情。她是一名大学辅导员,在处理班务的时候,她总是站在真正是非曲直的角度,站在学生的角度。看起来很像《极道鲜师Ⅱ》上的 山口久美子,并且一样是年轻的女老师[跟学生几乎一样大],同时也是 a bit beautiful。
领导向她施压要她评优评奖学金照顾走关系的人,她置之不理;学生只要不是真的人品不好或做错了什么可以跟她开玩笑,还能跟着她蹭饭;偶然自己的手机打错电话对方知道她是女的疯狂骚扰,她找一帮学生反过来恶搞那个男的,还骗他到世纪欢乐园放了一下午鸽子;同事生病了会跑去照顾;最看不起那些不靠自己本事只会混关系耍深沉打酒令的人~~~~~~~
也许在中国,这个人脉关系当道的社会,作为成人不得不妥协。但是我仍然敬仰敬佩我的这位真性情的同学。
有这样的同学,并且可以做朋友,真是幸甚、幸甚。
2007年5月8日星期二
3D引擎_摘抄
3D (Game) Engine运行在底层平台软件(WIN32 API,OPEN GL ,Direct Sound ,D3D...)上,属于上层的平台软件。对更上层的用户(游戏内容制作者而非程序员)提供一个接口,此类接口使得游戏内容制作者可以通过数据方式(比方表格)而非编程方式,或仅简单的脚本编程,制作游戏。
在3D方面,要将物体数据有组织地存储起来,通常使用DAG(有向无环图)数据结构。要将物体高效的显示出来,就有决定那些是无须画的(不画当然最快),就有BSP法、Portal、普通的CLIP方法等等大量的Culling算法。而物体之间的物理位置信息则要用碰撞检测去处理。
处理表格或脚本要Game Logic单元。预处理游戏者输入要事件响应单元...
可见3D Engine在D3D等上提供了大量的东西。目前的3D Engine仍留有很大的改进余地。全局光照仍无法实时实现。目前的碰撞检测的精度仍太粗糙。阴影的绘制尽管由于硬件的发展而产生了长足的进步,但仍无法做到速度与质量双满意...
总之,画三角形不难;把软件面对芯片架构优化以画的快一些也不是大题目。难得是能管理复杂场景,并将其高效、漂亮地画出来。这就是3D Engine要干的。
在3D方面,要将物体数据有组织地存储起来,通常使用DAG(有向无环图)数据结构。要将物体高效的显示出来,就有决定那些是无须画的(不画当然最快),就有BSP法、Portal、普通的CLIP方法等等大量的Culling算法。而物体之间的物理位置信息则要用碰撞检测去处理。
处理表格或脚本要Game Logic单元。预处理游戏者输入要事件响应单元...
可见3D Engine在D3D等上提供了大量的东西。目前的3D Engine仍留有很大的改进余地。全局光照仍无法实时实现。目前的碰撞检测的精度仍太粗糙。阴影的绘制尽管由于硬件的发展而产生了长足的进步,但仍无法做到速度与质量双满意...
总之,画三角形不难;把软件面对芯片架构优化以画的快一些也不是大题目。难得是能管理复杂场景,并将其高效、漂亮地画出来。这就是3D Engine要干的。
2007年5月7日星期一
因HD涉及到的系统性能与防震
author:nforcex
1. 无论Desktop PC还是Server,以现有的技术来看,性能瓶颈之所在位于I/O和硬盘。I/O是一个模糊而宽泛的概念,它的性能随着各种接口技术、传输技术的改进在不断提高中。而对于硬盘来说,由于其“机械手臂”这一先天不良的缓慢性导致一直鲜有提高,近7年来硬盘的寻道速度一直保持在8.5ms到10ms之间,没有显著进步。
最近一来,磁盘和主存的速度相差5个数量级,可想而知尽可能少的调用外存是提高速度的重要手段--内存增容、OS预加载常用进程的模块、pagefile.sys移至高速NAND 等等等等。
1. 无论Desktop PC还是Server,以现有的技术来看,性能瓶颈之所在位于I/O和硬盘。I/O是一个模糊而宽泛的概念,它的性能随着各种接口技术、传输技术的改进在不断提高中。而对于硬盘来说,由于其“机械手臂”这一先天不良的缓慢性导致一直鲜有提高,近7年来硬盘的寻道速度一直保持在8.5ms到10ms之间,没有显著进步。
最近一来,磁盘和主存的速度相差5个数量级,可想而知尽可能少的调用外存是提高速度的重要手段--内存增容、OS预加载常用进程的模块、pagefile.sys移至高速NAND 等等等等。
2. 另外,磁盘磁头距离盘片的距离是那样的近以至于它与灰尘高度的比例还要小于1米与从波士顿到加州的距离的比例。所以、、、、、、正在工作业已出鞘的磁头经不起震动,但是停机断电的磁头就好多了(磁头已经收了回去)。所以硬盘被誉为PC系统中最怕震的配件,剩下的也就Monitor了吧。
L1&L2 Cache of the K8(谈为什么AMD CPU的二级缓存不重要?)
author:nforcex
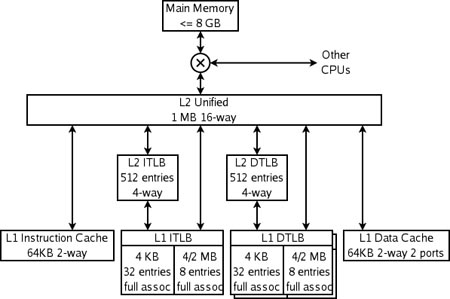
here is the cache hierarchy of the AMD Athlon64
The K8 has 4 specialized caches: an instruction cache, an instruction TLB, a data TLB, and a data cache. Each of these caches is specialized:
The instruction cache keeps copies of 64 byte lines of memory, and fetches 16 bytes each cycle. Each byte in this cache is stored in ten bits rather than 8, with the extra bits marking the boundaries of instructions (this is an example of predecoding). The cache has only parity protection rather than ECC, because parity is smaller and any damaged data can be replaced by fresh data fetched from memory (which always has an up-to-date copy of instructions).
The instruction TLB keeps copies of page table entries (PTEs). Each cycle's instruction fetch has its virtual address translated through this TLB into a physical address. Each entry is either 4 or 8 bytes in memory. Each of the TLBs is split into two sections, one to keep PTEs that map 4KB, and one to keep PTEs that map 4MB or 2MB. The split allows the fully associative match circuitry in each section to be simpler. The operating system maps different sections of the virtual address space with different size PTEs.
The data TLB has two copies which keep identical entries. The two copies allow two data accesses per cycle to translate virtual addresses to physical addresses. Like the instruction TLB, this TLB is split into two kinds of entries.
The data cache keeps copies of 64 byte lines of memory. It is split into 8 banks (each storing 8KB of data), and can fetch two 8-byte data each cycle so long as those data are in different banks. There are two copies of the tags, because each 64 byte line is spread among all 8 banks. Each tag copy handles one of the two accesses per cycle.
The K8 also has multiple-level caches. There are second-level instruction and data TLBs, which store only PTEs mapping 4KB. Both instruction and data caches, and the various TLBs, can fill from the large unified L2 cache. This cache is exclusive to both the L1 instruction and data caches, which means that any 8-byte line can only be in one of the L1 instruction cache, the L1 data cache, or the L2 cache. It is, however, possible for a line in the data cache to have a PTE which is also in one of the TLBs—the operating system is responsible for keeping the TLBs coherent by flushing portions of them when the page tables in memory are updated.
The K8 also caches information that is never stored in memory—prediction information. These caches are not shown in the above diagram. As is usual for this class of CPU, the K8 has fairly complex branch prediction, with tables that help predict whether branches are taken and other tables which predict the targets of branches and jumps. Some of this information is associated with instructions, in both the level 1 instruction cache and the unified secondary cache.
The K8 uses an interesting trick to store prediction information with instructions in the secondary cache. Lines in the secondary cache are protected from accidental data corruption (e.g. by an alpha particle strike) by either ECC or parity, depending on whether those lines were evicted from the data or instruction primary caches. Since the parity code takes fewer bits than the ECC code, lines from the instruction cache have a few spare bits. These bits are used to cache branch prediction information associated with those instructions. The net result is that the branch predictor has a larger effective history table, and so has better accuracy.
对于K8来说,AMD历来重视L1,64K Ins+64K Dat,2路组相联的设计让AMD拥有高命中率和低延迟的L1。然而在Instrution Cache中AMD的设计思路又与其它CPU有所不同。首先其Ins中并不存储传统的X86指令,而是存储着分支预测出来的X86指令的信息。再根据这些信息将指令解码成1~2条“宏操作”来执行。由于AMD CPU采用了3条流水线的超标量结构,因此其可以保证同时执行6条这样的宏操作。显然,相比之下AMD CPU的指令执行效率要优于Intel,因此就可以解释为什么AMD 2.4G可以打败Intel 3.2G了。 然而从这样的L1设计来看,似乎和Intel有些异曲同工之妙。
对于L2,AMD历来只有很少的256K或512K。这是由于AMD的Cache设计思想所致。在一般的Cache中,下级Cache总是要保留一个上级Cache的映象,即L1中的数据在L2中也能够找到。L2在L3中亦能够找到相同数据。然而AMD并没有这样做,它的L2中保存的数据都是L1中替换下来的,以保证CPU在下次使用中能够在L2中找到。因此,AMD的Cache结构呈现出L1+L2(L1与L2没有交集)的“怪异”现像,它的L2对于整体性能并不起决定性作用。Sempron 2600+(128K L2)同2800+(256K L2)性能相同,就是这个原因。
AMD L2不重要之Q&A:
Q:为什么K8 CPU的二级缓存不大却性能强劲?甚至只有Prescott架构(1MB或者2MB 2LCahce)的一半。
A:前言:在酷睿2推出之前,长达一年半的时间AMD占据了CPU性能的绝对优势。
抛开流水线长度比较短、分支预测方式以及集成内存控制器不说。K8架构采用了与Intel Pentium不同的Cache设计思想。在一般Cache中,下级Cache总是要保留一个上一级Cache的缓存,即L1中的数据在L2中能够找到,同样L2中的数据在L1中也可以找到(服务器CPU以及第四季度即将发布的K8L中将集成L3,很早以前,Intel在其工作站版PC解决方案中也包含L3,但那是集成于主板之上的。)然而AMD却没有这样做,它的二级缓存中保留的数据都是L1中替换下来的,这样CPU在下次使用中通过优先访问L2大大提高了效率--因为用户以及OS的操作往往是几个固定进程之间的彼此切换以及对内存中程序数据段的调用集中于小块区域。当然前述部分功能Intel也实现了。但是AMD的Cache结构是以怪异的“L1+L2”(L1/2没有交集)呈现在我们面前的,它的L2对于整体性能并不起决定性作用。所以,桌面版闪龙2800+的L2比闪龙2600+的小(前者256K后者128K)但是2800+的性能却更加强劲(不仅仅是因为频率提高了200MHz,还因为二级缓存对于AMD来说并不重要);所以,移动版的闪龙比Celeron-M更加强劲,Celeron-M因为二级缓存由Pentium-M的1M、2M降到512KB性能大大降低。
here is the cache hierarchy of the AMD Athlon64
The K8 has 4 specialized caches: an instruction cache, an instruction TLB, a data TLB, and a data cache. Each of these caches is specialized:
The instruction cache keeps copies of 64 byte lines of memory, and fetches 16 bytes each cycle. Each byte in this cache is stored in ten bits rather than 8, with the extra bits marking the boundaries of instructions (this is an example of predecoding). The cache has only parity protection rather than ECC, because parity is smaller and any damaged data can be replaced by fresh data fetched from memory (which always has an up-to-date copy of instructions).
The instruction TLB keeps copies of page table entries (PTEs). Each cycle's instruction fetch has its virtual address translated through this TLB into a physical address. Each entry is either 4 or 8 bytes in memory. Each of the TLBs is split into two sections, one to keep PTEs that map 4KB, and one to keep PTEs that map 4MB or 2MB. The split allows the fully associative match circuitry in each section to be simpler. The operating system maps different sections of the virtual address space with different size PTEs.
The data TLB has two copies which keep identical entries. The two copies allow two data accesses per cycle to translate virtual addresses to physical addresses. Like the instruction TLB, this TLB is split into two kinds of entries.
The data cache keeps copies of 64 byte lines of memory. It is split into 8 banks (each storing 8KB of data), and can fetch two 8-byte data each cycle so long as those data are in different banks. There are two copies of the tags, because each 64 byte line is spread among all 8 banks. Each tag copy handles one of the two accesses per cycle.
The K8 also has multiple-level caches. There are second-level instruction and data TLBs, which store only PTEs mapping 4KB. Both instruction and data caches, and the various TLBs, can fill from the large unified L2 cache. This cache is exclusive to both the L1 instruction and data caches, which means that any 8-byte line can only be in one of the L1 instruction cache, the L1 data cache, or the L2 cache. It is, however, possible for a line in the data cache to have a PTE which is also in one of the TLBs—the operating system is responsible for keeping the TLBs coherent by flushing portions of them when the page tables in memory are updated.
The K8 also caches information that is never stored in memory—prediction information. These caches are not shown in the above diagram. As is usual for this class of CPU, the K8 has fairly complex branch prediction, with tables that help predict whether branches are taken and other tables which predict the targets of branches and jumps. Some of this information is associated with instructions, in both the level 1 instruction cache and the unified secondary cache.
The K8 uses an interesting trick to store prediction information with instructions in the secondary cache. Lines in the secondary cache are protected from accidental data corruption (e.g. by an alpha particle strike) by either ECC or parity, depending on whether those lines were evicted from the data or instruction primary caches. Since the parity code takes fewer bits than the ECC code, lines from the instruction cache have a few spare bits. These bits are used to cache branch prediction information associated with those instructions. The net result is that the branch predictor has a larger effective history table, and so has better accuracy.
对于K8来说,AMD历来重视L1,64K Ins+64K Dat,2路组相联的设计让AMD拥有高命中率和低延迟的L1。然而在Instrution Cache中AMD的设计思路又与其它CPU有所不同。首先其Ins中并不存储传统的X86指令,而是存储着分支预测出来的X86指令的信息。再根据这些信息将指令解码成1~2条“宏操作”来执行。由于AMD CPU采用了3条流水线的超标量结构,因此其可以保证同时执行6条这样的宏操作。显然,相比之下AMD CPU的指令执行效率要优于Intel,因此就可以解释为什么AMD 2.4G可以打败Intel 3.2G了。 然而从这样的L1设计来看,似乎和Intel有些异曲同工之妙。
对于L2,AMD历来只有很少的256K或512K。这是由于AMD的Cache设计思想所致。在一般的Cache中,下级Cache总是要保留一个上级Cache的映象,即L1中的数据在L2中也能够找到。L2在L3中亦能够找到相同数据。然而AMD并没有这样做,它的L2中保存的数据都是L1中替换下来的,以保证CPU在下次使用中能够在L2中找到。因此,AMD的Cache结构呈现出L1+L2(L1与L2没有交集)的“怪异”现像,它的L2对于整体性能并不起决定性作用。Sempron 2600+(128K L2)同2800+(256K L2)性能相同,就是这个原因。
目前而言,英特尔拥有相对庞大得多的产能,因此在产品上喜欢加入较大容量的L2 cache,而AMD则希望以较小的L2 cache配合内建的内存控制器来获取适宜的性能/价格平衡,这也是当初加入AMD的DEC处理器研发人员所喜欢的架构策略。
L2 cache再大也是难以避免命中失败,当初DEC的Alpha处理器研发人员就一直很渴望把这样的损失透过集成内存控制器降低到最低。从性能角度出发,无疑是值得鼓励的。
AMD L2不重要之Q&A:
Q:为什么K8 CPU的二级缓存不大却性能强劲?甚至只有Prescott架构(1MB或者2MB 2LCahce)的一半。
A:前言:在酷睿2推出之前,长达一年半的时间AMD占据了CPU性能的绝对优势。
抛开流水线长度比较短、分支预测方式以及集成内存控制器不说。K8架构采用了与Intel Pentium不同的Cache设计思想。在一般Cache中,下级Cache总是要保留一个上一级Cache的缓存,即L1中的数据在L2中能够找到,同样L2中的数据在L1中也可以找到(服务器CPU以及第四季度即将发布的K8L中将集成L3,很早以前,Intel在其工作站版PC解决方案中也包含L3,但那是集成于主板之上的。)然而AMD却没有这样做,它的二级缓存中保留的数据都是L1中替换下来的,这样CPU在下次使用中通过优先访问L2大大提高了效率--因为用户以及OS的操作往往是几个固定进程之间的彼此切换以及对内存中程序数据段的调用集中于小块区域。当然前述部分功能Intel也实现了。但是AMD的Cache结构是以怪异的“L1+L2”(L1/2没有交集)呈现在我们面前的,它的L2对于整体性能并不起决定性作用。所以,桌面版闪龙2800+的L2比闪龙2600+的小(前者256K后者128K)但是2800+的性能却更加强劲(不仅仅是因为频率提高了200MHz,还因为二级缓存对于AMD来说并不重要);所以,移动版的闪龙比Celeron-M更加强劲,Celeron-M因为二级缓存由Pentium-M的1M、2M降到512KB性能大大降低。
2007年5月3日星期四
2007年5月1日星期二
新书试读
《Rootkits——Windows内核的安全防护》
最近最让IT管理员头痛的是什么呢?--毫无疑问是rootkit。这种可恶的程序是一批工具集,黑客用它来掩饰对计算机网络的入侵并获得管理员访问权限。一旦黑客获得管理员访问权限,就会利用已知的漏洞或者破解密码来安装rootkit。然后rootkit会收集网络上的用户ID和密码,这样黑客就具有高级访问权限了。
《超越C++标准库:Boost库导论》
谁说ANSI/ISO C++会陷入无穷无尽的底层机关?谁说只有JAVA才有高效的垃圾清理机制?看看C++的开源项目Boost吧,它为我们创造好了优秀的轮子。
最近最让IT管理员头痛的是什么呢?--毫无疑问是rootkit。这种可恶的程序是一批工具集,黑客用它来掩饰对计算机网络的入侵并获得管理员访问权限。一旦黑客获得管理员访问权限,就会利用已知的漏洞或者破解密码来安装rootkit。然后rootkit会收集网络上的用户ID和密码,这样黑客就具有高级访问权限了。
《超越C++标准库:Boost库导论》
谁说ANSI/ISO C++会陷入无穷无尽的底层机关?谁说只有JAVA才有高效的垃圾清理机制?看看C++的开源项目Boost吧,它为我们创造好了优秀的轮子。
订阅:
博文 (Atom)